

In Defense of “Artificial Intelligence” — a Book Excerpt
Why the historically abused term means much more than it used to

Note to readers
This is an excerpt from Chapter 1: What is Artificial Intelligence? of my forthcoming book Obsolete: The AI Industry’s Trillion-Dollar Race to Replace You—and How to Stop It (Nation Books). If you preorder through my publisher, you’ll get it in June. Everyone else will have to wait for the wide release, now on September 15th.
Some terminology introduced earlier in the book (and covered in this excerpt):
Artificial general intelligence (AGI) focuses on the wrong thing (thinking like a human) and has become abused past the point of usefulness. As a replacement, I introduce the Obsoleting Machine, which would be a machine that produces labor (elaborated on below).
Since a universal labor-producing machine is the goal of the AGI industry, I relabel it the Obsoleting Project.
More technical readers may want to skip the introductory section on deep learning.
“The original question, ‘Can machines think?’ I believe to be too meaningless to deserve discussion.” - Alan Turing
Researchers organizing a 1956 conference at Dartmouth coined the term “artificial intelligence” to describe their ambitious new field, confidently speculating that “every aspect of learning or any other feature of intelligence can in principle be so precisely described that a machine can be made to simulate it.” They told their prospective funder, the Rockefeller Foundation, that they expected “a significant advance” in domains such as “machine language use, self-improvement, and creativity” as a result of a “two-month, ten-man study.”

That initial optimism didn’t last, but the founders’ audacity set the tone for the entire field, inaugurating a recurring cycle of hype and disappointment that continues to this day. The moniker has since been criticized as a meaningless buzzword that companies use to “AI-wash” their decidedly low-tech software products. In this view, using “intelligence” to describe these systems is giving them far too much credit, hyping their benefits and masking their myriad social costs.
Certainly, companies do use AI as a marketing term to hawk their products, but “artificial intelligence” accurately describes the aspiration of the founders of the field: to build machines that can think like we can. Aspirations, of course, do not make reality, and AI’s most fervent boosters overhype the technology’s present and near-future capabilities. Meanwhile, its greatest skeptics often focus on semantic debates over what constitutes true “thinking” or “understanding.” To avoid both of these traps, we should focus on two questions: What can AI actually do? And how quickly is that changing?
The Obsoleting Machine does not yet exist. But today’s most capable general-purpose AI models—Anthropic’s Claude, OpenAI’s ChatGPT, Google’s Gemini—aspire to it. These are known as frontier models: systems at the cutting edge. They work somewhat like a consultant you can only hire once. Each can read up on the project, including what was done by previous consultants, but is only able to perform a finite amount of work before being replaced by a fresh one. They’re far cheaper than classic consultants and occasionally very useful, but not something that’s about to replace your whole workforce.
The actual Obsoleting Machine would be able to join the team indefinitely, execute the job end-to-end, and make traditional employment superfluous—leaving livelihoods safe to the extent a human touch is preferred or the jobs themselves are legally protected. The real-world difference between automating a process 99.9 percent of the way and 100 percent can be vast. As someone who has “nearly finished” his book about a dozen times, I can attest that last mile problems are everywhere. Autonomous vehicles and AI customer service agents still require some human intervention; people there still aren’t obsolete. Qualities like taste and intuition are hard to measure, but crucial to traversing that last mile.
Some doubt that today’s approaches to training AI are on the path to true machines that make labor. But if they’re correct, the Obsoleting Project will continue, redeploying its—now considerably greater—resources into finding a different path. This book is agnostic as to the shape the first Obsoleting Machine might take, but simply does not rule out the possibility that it could be built. Whether it’s possible in the next few years or next few decades matters far less than whether it’s possible at all.
Progress hasn’t been uniform. AI’s frontier has a jagged edge, with some capabilities—processing speed, general knowledge—already at superhuman levels and others—interfacing with the real-world, executing long-term tasks—well below. There’s a classic adage: “AI is whatever hasn’t been done yet.” With growing difficulty, we can still point to ways leading AI models fail at something a child could do, while the breakthroughs in Go or chess that experts once believed to be a century away or downright impossible are metabolized quickly.
But what if the progress doesn’t stop? Can we really feel comfortable risking everything on the assumption that it will? Seven decades after the original Dartmouth AI conference, the field’s grand ambition no longer looks so implausible.
Deep learning
Since around 2012, a single approach to developing AI, deep learning, has driven progress across nearly every domain—powered by the same forces: more data, more computing power, better algorithms. That shared engine is what makes “AI” a coherent subject now in a way it wasn’t before.
The most significant feature of deep learning models is that they are grown, not programmed. They’re composed of layers of artificial neural networks, loosely inspired by the brain: algorithms train a model by adjusting its “neurons” based on examples in massive datasets to produce ever better results, whether it’s distinguishing a dog from a cat in an image or transcribing speech to text.
Programmers today can dig into traditional software to trace exactly how inputs turn into outputs; deep learning models, in contrast, are black boxes. The final product isn’t a tidy set of rules, but sprawling tables of model weights or parameters: billions to trillions of numbers that, while technically legible, tell us about as much about the model’s behavior as the first human genome told us about how people would act. As the AI developer Connor Leahy told me, “It’s more like we’re poking something in a Petri dish” than writing a piece of code. Nevertheless, these systems work—far better than past efforts to make machines intelligent.
The deep learning era began in 2012, when Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton—armed with two graphics cards from an obscure gaming company called Nvidia—trained a deep neural network called AlexNet that decisively outperformed traditional approaches in a famous image recognition competition, prompting a tectonic shift in the field. And in 2020, OpenAI researchers discovered “Scaling Laws:” equations that could predict—with remarkable precision—how much better language models would get as you increased model size, dataset size, or computing power (i.e. “compute”) used.
This insight is sometimes misunderstood as meaning that AI gets exponentially better as you scale up inputs. But it’s really the opposite: it takes exponentially greater amounts of data, compute, and parameters just to keep improvements coming. As Oxford philosopher Toby Ord observed of the “Scaling Laws” paper, halving the model’s error rate required a million-fold increase in compute. If every time you wanted to double the resolution of a photograph, you had to spend a million times more on your camera, we’d probably learn to live with fuzzy photos. But the Obsoleting Project isn’t trying to make a better camera, it’s trying to make a machine that makes labor.
The field has compensated for this dreadful return on investment by scaling up everything at once. Since 2012, the amount of compute used to train leading models has increased 4.5 times per year, coming out to more than a hundred-million-fold increase. Predictable, but ever more expensive, gains help to explain why so much capital is flooding into AI companies and data centers.
The combination of massive compute scale-ups and better training methods has produced systems that advanced far faster than even AI experts expected. Deep learning models now match or exceed human performance across a growing range of tasks, such as image recognition and reading comprehension. Moreover, the time taken to get there has shrunk dramatically in the last few years.
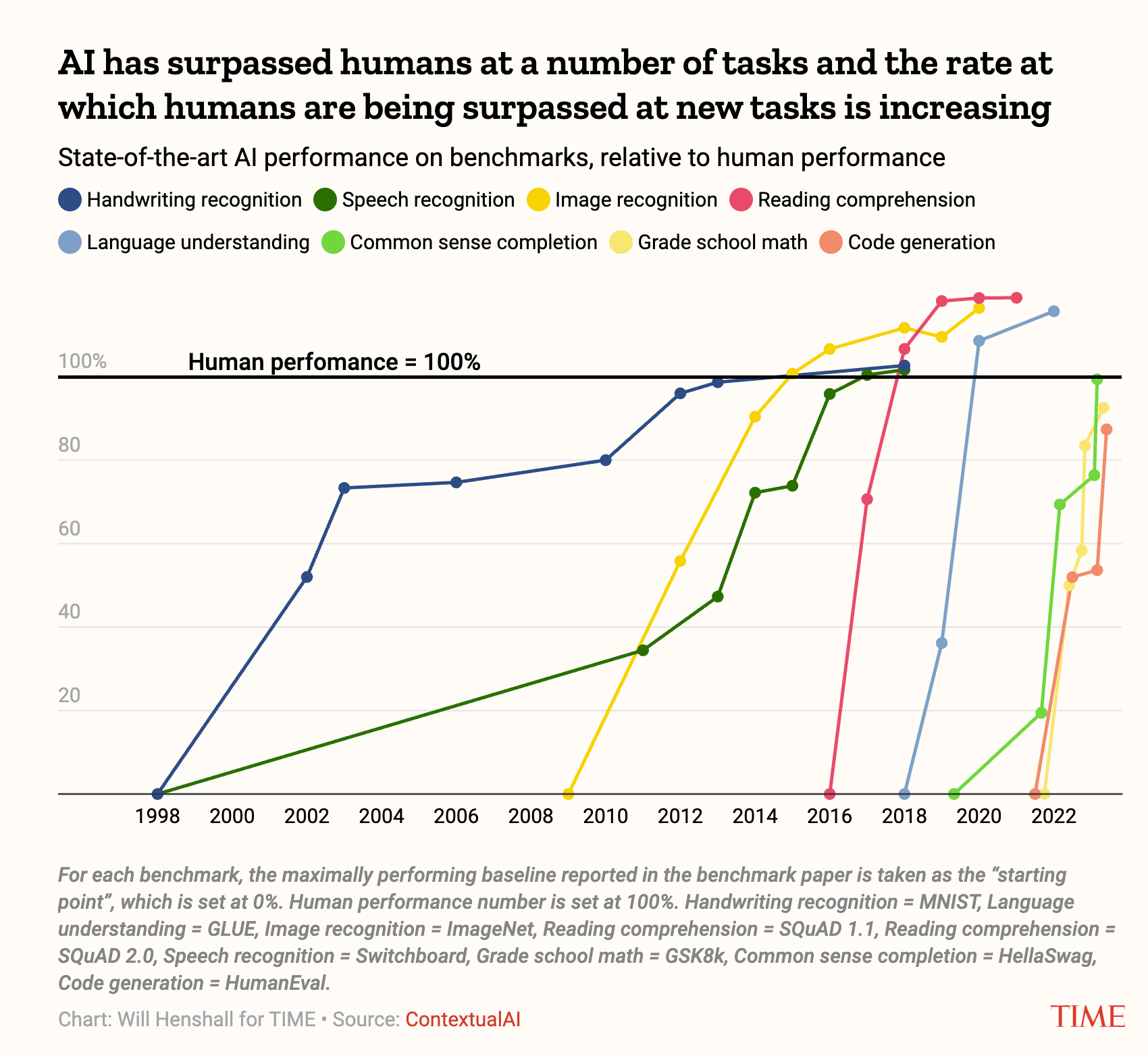
One of the most significant features of deep learning systems is that as models get larger, they do more than just repeat what they’ve seen before. Instead, researchers are often surprised by how new capabilities emerge suddenly, allowing models to tackle tasks they were never explicitly trained to solve.
The world mostly didn’t realize how far deep learning had come until November 30, 2022, when OpenAI released a “low-key research preview” with a name clunky enough to match it. ChatGPT shocked the world, which, in turn, shocked the company. OpenAI hadn’t expected much from its chatbot, which was fun, but not that useful. Within two months, ChatGPT amassed 100 million monthly active users—by far the fastest uptake of any consumer app.
But it was the March 2023 release of GPT-4 that really impressed—and spooked—insiders. The improvement over GPT-3.5, which powered ChatGPT at launch, was obvious. The pace, however, was partly an illusion. OpenAI had been sitting on GPT-4 for seven months, and it took another full year for anyone else to take the lead, with a real, but more incremental, improvement. Hype and fears subsided accordingly.
AI progress didn’t actually stop though, it had just become invisible to most people. “Reasoning” models, beginning with OpenAI’s o1 in September 2024, rapidly advanced anywhere you could automatically verify an answer, such as solving a math problem or fixing a software bug. This meant that progress increasingly concentrated in technical domains like programming, while squishier, more legible domains, like writing, stagnated. This helps explain why AI was purportedly hitting wall after wall—all while programmers, scientists, mathematicians, and cybersecurity experts noticed that, suddenly, these “reasoning” models could really help them with their work.
The next leap was harder to miss. AI agents—aspirationally, systems that can do whatever humans can do from a computer—had long been promised and long been underwhelming. But in November 2025, Claude Code with Opus 4.5 crossed a critical threshold. Claude Cowork, basically Claude Code with a user interface, was, Wired declared “an AI agent that actually works.” And according to Claude Code’s creator, Cowork was also completely written by Claude Code. When the leading benchmark of realistic computer use was published in April 2024, the best agent scored just 12 percent, while humans got 72 percent. It only took until February 2026 to surpass that, when Anthropic reported Claude Opus 4.6 scored 72.7 percent.
Yet, somehow, we still need humans. What gives?
Resolving the paradox of artificial intelligence
If you met someone who aced nearly every standardized test and professional exam in existence, outclassed STEM PhDs in tests from their fields, and scored gold in international math and programming Olympiads, you could reasonably expect them to have their pick of well-compensated jobs. If millions of such people appeared overnight, you might anticipate scientific breakthroughs and a transformed economy. Today’s frontier AI models resemble this hypothetical polymath, but they haven’t yet driven massive labor automation or made any Nobel-worthy discoveries.
To resolve this apparent paradox, the AI evaluation nonprofit METR tried to figure out what AI can do, measured by how long it would take a human to do the same. The “task completion time horizon” metric draws on how long it took programmers to complete nearly 200 novel, realistic tasks across coding, cybersecurity, general reasoning, and machine learning. METR then determined the longest task, in human-time, top AIs could complete.
Two findings jumped out immediately. First, AIs couldn’t handle long tasks well. When the metric was introduced in March 2025, the best-performing model’s time horizon was around 50 minutes, and that’s just at 50 percent reliability. As study coauthor Ben West told me: “If you think [about] what economically valuable work can you delegate to a very smart person that they can do in one hour, the answer is not very much.”
Second, and far more important, AI time horizons are doubling—every 8.5 months initially, before compressing to every 105 days starting mid-2024. GPT-2, released in 2019, failed on tasks requiring more than a few seconds of human effort. By February 2026, Claude Opus 4.6 had a 50 percent completion time horizon a hair under 12 hours. The absolute gain over the nearly 6-hour horizon achieved by GPT-5.2—released less than two months earlier—is greater than the previous almost six years of progress.
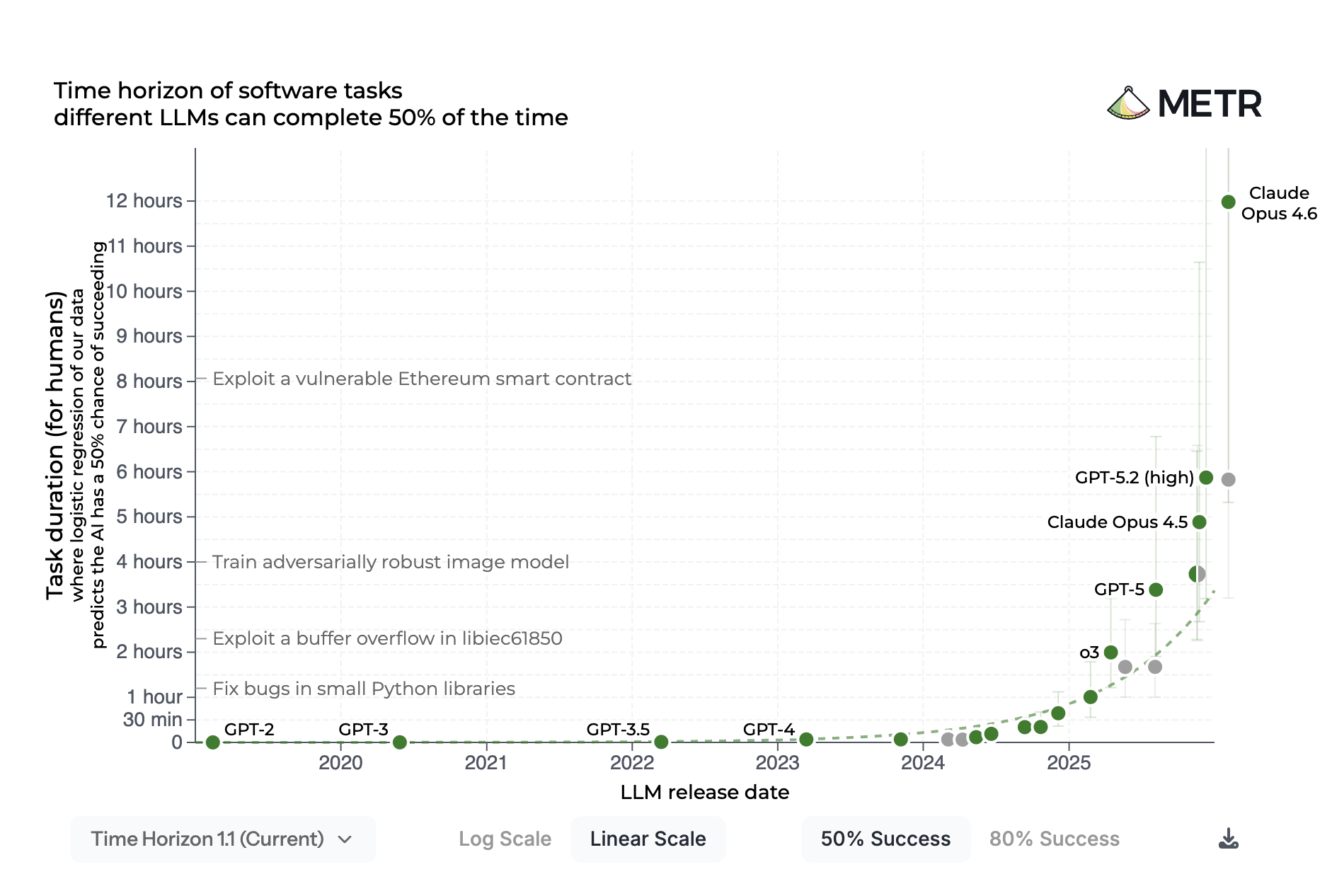
By now, it’s clear that AIs have gotten pretty good at coding, the focus of this benchmark, so how much does it really tell us about AI progress?
A far lesser known follow-up analysis from METR tested time horizons across nine additional benchmarks—including PhD-level STEM knowledge, mathematics, autonomous driving, computer use—and found the same exponential pattern in every single one. The absolute levels vary widely: AI handled hour-plus coding tasks but struggled beyond a few minutes at visual computer use (like updating a book-keeping spreadsheet using photos of recent receipts). Yet every line on the graph shows real, if varied progress, with most doubling every two to six months.
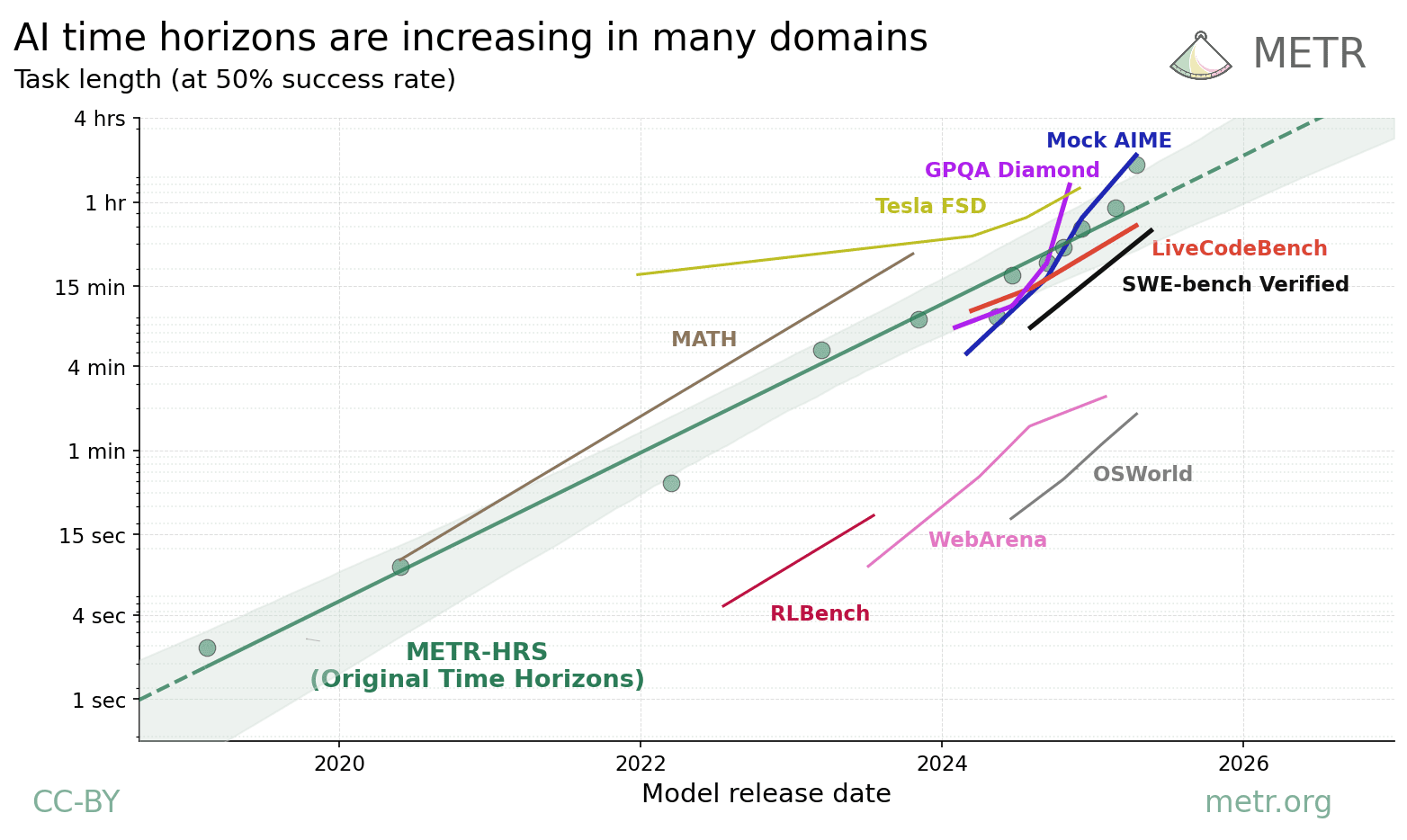
However, there’s a big caveat to all of this: anything that can be automatically graded is, by its nature, something AI can get very good at. The near-universal trend is: researchers introduce a new benchmark even the best models struggle with. But as soon as AIs start making any traction on it, the benchmark is quickly “saturated” as scores approach the maximum. The time horizon approach solves the saturation problem, but not the deeper one—which is why METR freely admits “all benchmarks are somewhat artificial.”
Because most things in life don’t resemble tests, this creates a gap between how capable AI is on benchmarks and how useful they are IRL. There’s also a huge bias in what benchmarks are created in the first place, with the overwhelming bulk of effort going toward measuring coding, with business and finance operations a distant second.
The benchmark gap widened with the introduction of the aforementioned “reasoning” models, which use an internal scratchpad to step through problems and are trained with reinforcement learning that rewards correct outcomes. AI safety researcher Jeffrey Ladish told me that “reasoning” models exemplified an industry-wide shift from predicting the next word and pleasing human raters to learning how to “be successful and competitive.” We’ll see that these models really did improve in technical domains, just not as dramatically as benchmarks would suggest.
For instance, in an influential evaluation using programming tasks pulled from real open-source codebases, METR found that half of all AI-generated, “passing” solutions were actually rejected by project maintainers. When accounting for this gap, the researchers estimated Sonnet 4.5’s 50-minute horizon became around eight minutes—a seven-fold decrease. (Opus 4.6 wasn’t available during this study, but dividing its 50 percent reliability horizon by seven gets you around 1.75 hours.) A seven-fold difference would be made up in a few doublings, but adjusting for the gap suggested the doubling time could be significantly longer too (though the authors caution the data is too sparse to conclude anything confidently here).
So can AI actually aid useful work, or does it just ace tests? METR tried to find out directly. In another famous experiment, researchers randomly disallowed experienced open-source developers from using AI tools. The participants, using early 2025 models, felt AI assistance had made them about 20 percent more productive. The actual measured effect? Access to AI reduced output by 19 percent. The “AI is a scam” camp celebrated it as proof that AI was merely tricking us into thinking it was helping.
But when METR tried running a follow-up that August, the researchers struggled to recruit developers, who were now much less willing to forgo AI tools. And for those from the original cohort who returned, AI actually did make them nearly 20 percent more productive. METR notes “the true speedup could be much higher among the developers and tasks which are selected out of the experiment.” The researchers are redesigning the study “due to the severity of these selection effects.” I feel for them. They’re trying to measure a rapidly moving target: between the end of each experiment, AI’s 50-50 time horizon increased 12-fold.
When you zoom out using metrics like METR’s time horizon, AI progress looks remarkably smooth: exponential growth, year over year. But we experience that progress in fits and starts, when capabilities reach obvious tipping points. Often, we just aren’t exposed directly enough to AI’s jagged cutting edge.
The ones staring at it every day have started to sound rattled. OpenAI cofounder, former Tesla AI chief, and coiner of “vibe-coding” Andrej Karpathy reported in late 2025 that he’s “never felt this much behind as a programmer… Clearly some powerful alien tool was handed around except it comes with no manual.”
If you’re looking for a manual to the industry trying to render you obsolete, you’ll love the book.
And if you enjoyed this, please share it with someone else who might!
Thank you ordered