

No, AI Progress is Not Grinding to a Halt
A botched GPT-5 launch, selective amnesia, and flawed reasoning are having real consequences

The growing media consensus is clear: GPT-5 is a disappointment that signals AI progress is hitting a wall. But this juicy narrative is wrong, a potent example of expectations shaping reality.
For insiders, the release of GPT-4 was perhaps more significant than the initial release of ChatGPT a few months earlier. The new model was significantly better than the previous, GPT-3.5, which was useful as a proof of concept, but not for much else.
GPT-4, on the other hand, appeared to be actually useful. Duolingo, Khan Academy, Microsoft, Stripe, Morgan Stanley, Github, and others incorporated the new model into new or existing products.

Soon after GPT-4’s release, leading AI researchers like Geoffrey Hinton and Yoshua Bengio began publicly warning that advanced AI could pose an existential risk to humanity. These alarms coincided with major public statements, including an open letter calling for a six-month pause on frontier AI research — signed by Elon Musk, Steve Wozniak, Yuval Noah Harari, and others — and a widely endorsed declaration that mitigating the risk of AI-driven extinction should be a global priority, a stance backed by hundreds of top AI researchers and the leaders of the major AI companies.
AI safety was having a moment. And it was largely downstream of the perception that AI was farther along than most people realized — even many insiders — and it was moving faster than almost anyone expected.
Now, two and a half years later, GPT-5 is finally here. But the most anticipated AI release of all time is having the opposite effect. New Scientist pronounced that, “GPT-5's modest gains suggest AI progress is slowing down.” The disappointing new model prompted the New Yorker to ask, “What if A.I. Doesn’t Get Much Better Than This?” The Financial Times posed the question: “Is AI hitting a wall?”
But these obituaries for AI progress are greatly exaggerated. There are specific issues in many of these articles, but there’s a bigger, much more fundamental one: They’re not comparing like with like.
GPT-5 is being compared not to its generational predecessors, but instead to a crowded field of competitor models released within the last few months. GPT-4, on the other hand, is being compared to much older technology, developed before the generative AI industry even existed.
What GPT-4 was actually like
If GPT-4 came out today, it would be dead on arrival.
The model that shocked the world back in March 2023 could handle just 33,000 tokens at a time (think of tokens as words or chunks of words). GPT-5 can handle 400,000. Processing a million tokens on GPT-4 cost $37.50; on GPT-5, it’s just $3.44.
On a composite of leading benchmarks, GPT-4 scored 25 out of 100. GPT-5 gets a 69. In fact, at least 136 newer models now outperform GPT-4 by this measure.
When ChatGPT launched in late 2022, it was built on GPT-3.5 — a model fine-tuned to be more conversational. That was already nearly a year behind the curve, since InstructGPT (an earlier version) had come out in January 2022, and GPT-3 itself was released in May 2020, 34 months before GPT-4.
Basically, ChatGPT was iterating on technology that was nearly a year old, which was itself iterating on technology that was nearly two years old. But after GPT-4, new models started coming out almost as soon as they were trained, as competitors scrambled to keep up. The gap between public releases and the cutting edge narrowed fast.
In the New Scientist article, Alex Wilkins writes that GPT-5 “has improved on GPT-4, but the difference for many benchmarks is smaller than the leap from GPT-3 to GPT-4.”
When Obsolete asked which benchmarks he was referring to, Wilkins explained that it’s tough to compare models directly years apart — many of the old benchmarks aren’t even used anymore — but pointed to two examples. On the MMLU test (a big-picture knowledge quiz for AIs), GPT-3 jumped from 44 percent to 86 percent when GPT-4 arrived, while GPT-5 only managed a few more points. HumanEval, a coding benchmark, showed a similar pattern: GPT-3 got nothing right, while GPT-4 scored 67 percent and GPT-5 hit 93.4 percent.
This is what you’d expect: Once a model gets close to maxing out a benchmark, there’s less room for a dramatic jump. This effect — called “saturation” — makes it literally impossible to see another leap like the one from 3 to 4 on these particular tests.
Because of this, it’s hard to find any benchmarks that stick around long enough to compare models years apart. I tried to look up GPT-4’s scores on the eight main benchmarks used in a recent composite — and could only find one, from a later version of the model.
But where it’s possible to approximate a head-to-head comparison on unsaturated benchmarks, the difference is massive. For example, on SWE-Bench Verified — a tough, real-world coding test — GPT-4 Turbo (from late 2023) solved just 2.8 percent of problems. GPT-5 solved 65 percent. On a set of difficult math problems, GPT-4o (from May 2024) scored just 9.3 percent, while OpenAI reports GPT-5 Pro gets nearly 97 percent without tools, and 100 percent with them.
A cleaner way to compare models released years apart is METR’s “task-completion time horizon” — the human labor-time of programming tasks that a model can do at a given success rate. METR finds the horizon doubled roughly every seven months since 2019, accelerating to every few months in 2024 and 2025.
METR estimated that GPT-3 could handle tasks that took human programmers nine seconds at a 50 percent reliability. GPT-3.5 inched that up to 36 seconds, and GPT-4’s equivalent figure was five minutes — a 3,230 percent increase over GPT-3. GPT-5 scored two hours and seventeen minutes — a 2,640 percent improvement over GPT-4.
So this suggests a relative slowdown (though GPT-5 came out 29 months after GPT-4, five months less than the gap between 4 and 3). But most ways you slice it, GPT-5 represents a massive step up from GPT-4, potentially in the same ballpark as the leap from 3 to 4 and likely surpassing the jump from 3.5 to 4. The latter is perhaps most relevant, as this was the experience of early ChatGPT users who got upgraded to the model and were astonished.
But the difference between GPT-3 and its successors wasn’t just about bigger numbers on benchmarks — it was about crossing fundamental capability thresholds. The original GPT-3, could barely follow instructions. Training InstructGPT and then GPT-3.5 — models that could follow instructions with no examples needed (i.e. “zero shot learning”) — was the unlock that created the “ChatGPT moment” and pushed generative AI into the mainstream. Some jumps in capability open up entire new frontiers; others are just incremental. As models get better, there’s simply less uncharted territory left, and the ground that’s left to cover is, almost by definition, less transformative.
However, the instruction-following part of GPT-3 came in 2021 in the form of a model called text-davinci-001 (OpenAI’s naming prowess has a storied history), as you can see for yourself in these comparisons between GPT generations.

And for the most part, these benchmarks don’t capture important parts of the experience of using the model. When GPT-4 came out, it could take in text and images, and output only text. This functionality was enough to shock the world, but add in the ability to search the internet, write and run code, generate images, talk to you, and function as a Shazam-for-everything — then imagine how the world would have responded.
The real consequences of false narratives
But people aren’t comparing 5 to 4 — they’re comparing 5 to competitor models that have been released within the last few months, finding that it’s not utterly dominating all of them at everything and concluding that it means progress is slowing down.
This doesn’t make much sense.
Nonetheless, the narrative appears to be ossifying in elite circles with real policy consequences. “It’s honestly fascinating how widely ‘what is gonna happen now that GPT-5 is a failure’ has already percolated in the DC world,” tweeted AI safety advocate Dave Kasten, who clarified: “(I don’t think GPT-5 was a failure).”
Two days after GPT-5’s release, David Sacks, Trump’s AI czar, wrote a long post on X saying, among other things, that, “The Doomer narratives were wrong,” and, “Apocalyptic predictions of job loss are as overhyped as AGI itself.”
Sacks’ pronouncement was followed shortly thereafter by President Trump’s decision to allow Nvidia to sell its H20 chips to China, which had previously been blocked as part of U.S. semiconductor export controls. The H20 chips are substantially less powerful for training AI models than Nvidia’s leading chips, but are still very effective at running AI models, where an increasing share of the computing power is directed.
Last week, the Financial Times reported that the Chinese AI startup DeepSeek was “encouraged by authorities” to use Huawei chips to train its successor to its R1 “reasoning” model, which triggered a trillion-dollar selloff of tech stocks in January. The Huawei chips reportedly couldn’t get it done, so the company switched back to using Nvidia chips.
The Financial Times story about how GPT-5 suggests AI progress is stalling quotes a think tank researcher who said the Trump administration is working now to help other countries adopt American AI, and that, “This represents a significant departure from previous efforts, and is likely due to a different belief in the likelihood of a hard AGI take-off scenario.”
There’s also a quote from former OpenAI head of policy Miles Brundage that jumped out at me: “It makes sense that as AI gets applied in a lot of useful ways, people would focus more on the applications versus more abstract ideas like AGI.” Brundage led AGI Readiness at OpenAI until he resigned in October and said clearly that the world is not ready for AGI. I asked him about it, and he said the FT cut off his full quote, which he then posted on X. Here’s how it continues:
But it’s important to not lose sight of the fact that these are indeed extremely general purpose technologies that are still proceeding very rapidly, and that what we see today is still very limited compared to what’s coming.
This is, frankly, egregious. If an editor insisted on using someone’s quote in this misleading of a manner, I would walk away from the piece. After Brundage called this out on X, the FT updated the piece but didn’t mention the change in a correction.
Overall, it’s hard not to come away with the feeling that the FT decided on a narrative in advance and shoe-horned the evidence to back it up after the fact.
And as the dust settles after one of the bumpiest tech releases in recent memory, the failure of GPT-5 may also have been greatly exaggerated.
During an on-the-record dinner with journalists last week, Altman said that business demand for OpenAI’s models doubled after the GPT-5 release. How durable that supposed demand increase is remains to be seen, but it points to excitement from a segment of customers that the company had been ceding to competitors like Anthropic.
Why there might not be another GPT-4 moment
When OpenAI released ChatGPT, it had no real competition, and the company was already sitting on a far more capable model. But in releasing its chatbot, OpenAI essentially created the generative AI industry, which has become perhaps the most competitive market on the planet. Rivals are releasing models that outperform the state of the art, sometimes while also deeply cutting prices, at a near-monthly clip.
And by default, people seem to compare new releases to the best-available alternatives.
Because of all this, it’s unlikely that anyone will pull off a GPT-4 moment ever again, until and unless someone builds AI systems that can automate AI research and development. And if that does happen, there will be a powerful incentive to keep your discovery under wraps, quietly using it to bootstrap your own work and stack the deck further in your favor. (This would create serious risks that aren’t covered by many voluntary commitments, company safety policy, and regulations, which focus far more on deployment.)
At the same time, much of the progress being made is effectively invisible to non-experts. As I argued in Time in January, the biggest recent advances are happening in technical domains, like programming and math, where “reasoning” models — systems that spend more time “thinking” before answering — have been making rapid, but largely illegible, gains.
The combination of these dynamics, along with the massive failure of the mainstream media to correctly parse them for the public, is creating a boiling frog situation. AI progress is continuing at a fairly steady rate. GPT-5 might represent a relative slowdown compared to the ludicrous pace we’ve grown accustomed to, but it definitely doesn’t signal stagnation.
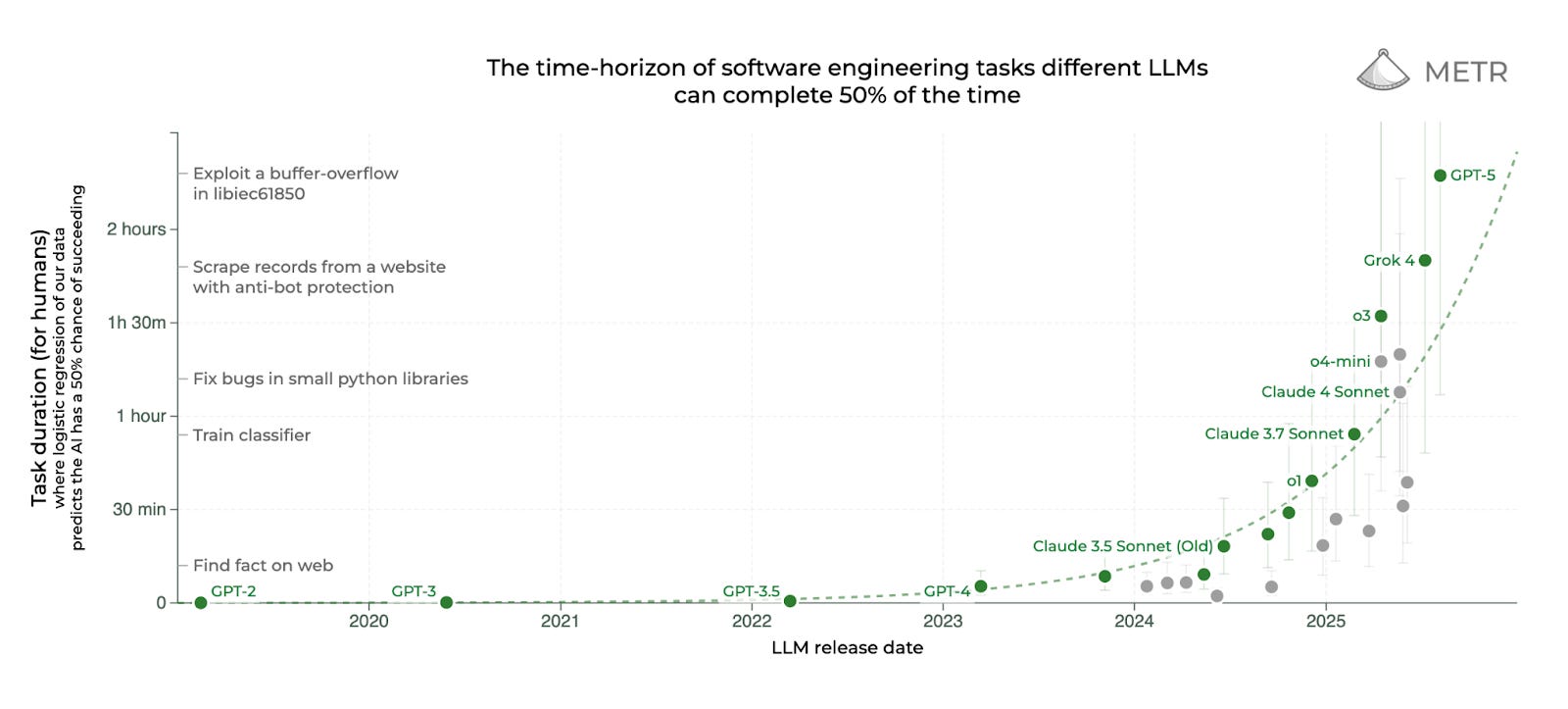
There are real questions of how much AI benchmarks capture real-world performance, highlighted by surprising recent research from METR. One experiment suggests that AI tools can actually hurt programmers’ productivity while creating the impression they’re helping. Another found AI code that passes automated tests actually needs a lot more work to be useable. (Obsolete will explore these findings and their significance in more detail in a companion piece.)
Sam Altman’s mistakes
The irony of all this is how much it comes down to decisions made by Sam Altman and OpenAI.
Altman has said a lot of things over the years about how he’s prioritizing AI safety — pursuing open source development, building AGI sooner when there will be less spare computing power lying around, structuring OpenAI as a nonprofit — that he has abandoned without much explanation. Perhaps Altman’s only surviving safety plan is one of “iterative deployment,” in which AI developers steadily release improved AI models, giving the world a chance to metabolize the progress and respond appropriately.
By these lights, ChatGPT represents a big win. It did more than anything ever has to alert the world to how far along language models had come. The release of GPT-4 soon after created the sense that progress was happening uncomfortably fast and that policymakers should really do something about this.
However, the bungled release of GPT-5 is now doing the exact opposite, at a time when the absolute capability levels of AI are higher than ever and progress toward automated AI R&D shows little sign of slowing down.
This is a consequence of many things, namely, OpenAI’s horrific naming practices (o3 is a far more capable model than 4o, obviously), the fierce competition ChatGPT kicked off, and Altman’s overhyped claims about how the new model scared him and was like having a PhD advisor on any topic.
Specific mistakes made by the company in the rollout of GPT-5 also played a big role, such as the baffling and quickly abandoned choice to shut down all the old models with no warning, technical bugs during the launch, and a lack of transparency in what model was giving you which answer — all of which overshadowed the ways in which the new model represented a meaningful upgrade along many dimensions.
OpenAI also created a mini-GPT-4 moment in December, when it announced its second-generation of reasoning model, which advanced the state of the art by double-digit percentage points on some of the hardest math, programming, and science benchmarks — months after its first generation reasoning model did the same. The company could have labeled this model GPT-5, and it probably would have seemed more worthy of the name.
Ultimately, iterative deployment as a safety strategy may be intrinsically flawed. Incremental improvements to AI systems are now quickly metabolized as nothingburgers by a media and public whose expectations were set unrealistically high by the shocking back-to-back releases of ChatGPT and GPT-4.
To see the danger of this kind of thinking, look no further than OpenAI’s release of its first open-weight models since GPT-2. It’s trivial to remove safety features from open-weight AI systems, resulting in something resembling a permanently jailbroken model. To show that the model was safe to release, OpenAI tested to see if it could enable bad actors to make bioweapons, concluding that, “Compared to open-weight models, gpt-oss may marginally increase biological capabilities but does not substantially advance the frontier.”
But iteratively deploying open-weight models that only marginally increase biorisk inches you closer and closer to releasing one that is actually capable of guiding someone through all the steps required to start a pandemic. And once the weights are published, it will be exceedingly difficult to unpublish them.
Edited by Sid Mahanta.
This piece incorrectly listed GPT-4’s context window as just 8,200 tokens, but there was actually a 33,000 token version at launch, as well. I regret the error.
Love this. Legacy media showing its true colors again, to the detriment of all
A POV re your take on "...and was like having a PhD advisor on any topic". I strongly disagree. I've had a PhD supervisor and been around many. GPT5 is smarter and more useful
There's a question I like to think about and is ~to your throughline, but it isn't very PC: if a model were smarter than me, how could I tell? If it got twice as smart from there, how could I tell?
To that is the AGI asymptote idea:
https://www.latent.space/p/self-improving?img=https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fd1c06950-0bb2-4f66-af8a-b51e3d5f446e_2110x952.png&open=false
GPT4 wasn't smarter than me, o3 was debatable, I can't keep up with 5. Neither can my friends.
Some PhD level stuff 5 has helped me with:
- correctly diagnosing a complex lifelong postural/physiotherapeutic issues re a back injury
- correctly interpreting brain MRI scans and blood tests. My neurologist - no joke - just implements theses that 5 reasons out
- discovered a diagnosis in the context of autoimmune disease symptoms (these are extremely complex, notoriously difficult to pin down)
- synthesized new and functional frames in an LLM consciousness project after comprehensive literature review in 4E cogsci
- took a loose mathematical intuition, formalized it into a conjecture, proved it, generalized it, proved it again, found a significant open problem in number theory that it applies to, sketched a proof
- found a nontrivial and original analysis of the economics of the AI supercycle
My even hotter take is that even the narrative of "pre-training progress is slowing" is also false, with pretty real consequences.